
World of methodologies | Supervised machine learning and classifiers
We took the first glimpse into the world of methodologies earlier this year when Medaffcon’s Data Analysis Lead Iiro Toppila opened the featured blog posts. During the autumn, Iiro returned to write about methods, so today we can learn more about machine learning. The core of today’s featured blog post is machine learning classifiers. They are a family of wonderful methods, each worth a lecture or two. However, the concept of a classifier is relatively simple. Therefore, they are one of the first methods that a data-scientist encounters during their career. Thus, our “world of methodologies” will start too with the classifiers.

The field of machine learning is large, and constantly evolving. Thus, diving into its secrets needs to be done gradually, piece by piece. And we cannot avoid the simplification of things in the beginning. So, roughly speaking, machine learning methods can be divided into two categories:
- Supervised (machine) learning – a family of methods, where the models are trained via examples with labeled data
- Unsupervised (machine) learning – a family of methods, where the models seek and find relations, connections, and shapes in the data, without separate examples or labels
Classifiers belong to the first above-mentioned, supervised machine learning. There are multiple different methods, but they all share a common idea. The goal is to train a machine to classify things by presenting them with multiple examples with known answers. Selecting the exact method is also limited by the type of data – but we’ll get back to this in the upcoming posts. The goal of classifiers is to assign each sample to one (or several) categories, based on the other features in the data.
“Let the machine learn what is important, and make the decisions based on what was learned.”
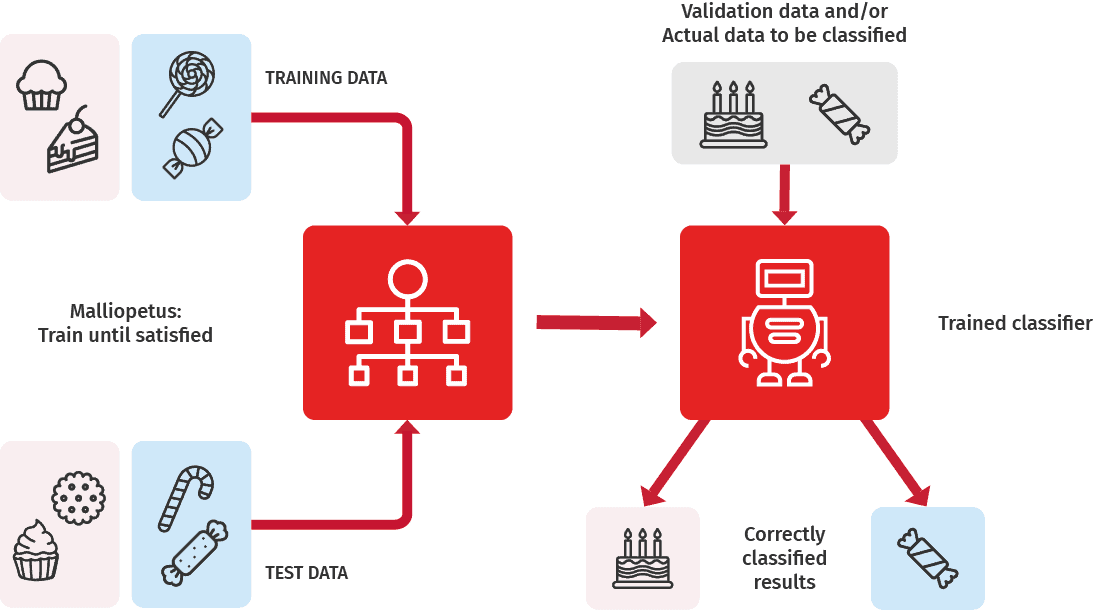
A general recipe for training a classifier:
- Present the machine (selected algorithm) with data, including the right answers (labels). Next, the machine should guess these labels based on the features in the data. Let the machine make a model to generate guesses.
- Test the model using another dataset that was not used in the first step. Check how close the guesses were compared to the ground truth. Make changes to the guessing model. First big, later smaller ones.
- Repeat steps 1 and 2 until you are satisfied i.e., the majority of the guesses were correct.
- Validate the final model using a third dataset, that was kept hidden from the model until now.
- Declare the model and the “sophisticated guesses” it made as good and have faith that the model will work also in the future with other corresponding data.
- When more data is accumulated, further train the model, and closely monitor its performance
You could compare this process to a junior pastry chef, who tries to come up with a perfect recipe for a perfect cake. The pastry chef starts with a solid guess on the recipe. He adds various ingredients based on a hunch, bakes the first cake, and tastes it. If the outcome of the used recipe is not good enough, the little baker makes some adjustments to the recipe, baking the next cake. This will continue until the junior chef considers the recipe and outcome as perfect – or at least good enough. Finally, if there is still some flour and eggs left, someone else might get to taste the recipe and so-called perfect cake. If the external board agrees on the taste, the cake could have a good chance to be selected among the treats sold in a fancy bakery – or even a huge supermarket. Once in production, the recipe can be further improved based on accumulated client feedback.
From a machine’s point of view, start working, repeat the task tirelessly, correct your work via trial and error, until it is performed flawlessly.
From theory to applied health
Methods such as machine learning classifiers could be used in healthcare for example to generate prediction models to identify high-risk patients. Using real-world data (RWD), it would be possible to collect massive datasets, that contain both the high-risk and low-risk patients, i.e., those who suffered the unfavorable health outcome, and those who avoided the harm. From this data, it would be possible to identify the factors that separate these patient groups from each other using machine learning algorithms. The more sophisticated methods can detect nonlinear associations and complex patterns of various factors, instead of traditional associations (diagnosis X does not increase the risk, if the patient is relatively young, and makes constant purchases of prescribed medications Y).
Classifiers are a viable option whether you are interested in understanding the actual factors that are associated with the event, or if you are interested in generating a as good as possible prediction model for clinical use. Naturally, both have a huge potential to assist and improve the daily work of attending clinicians – and indeed generate health from data.
As a simple extension of classifiers, corresponding machine learning methods can generate continuous variables instead of categorical classes. For example, probabilities for the risk of adverse health outcomes. Depending on the setting, also this type of information could be valuable for the clinician or the patient his/herself when assessing the risk of each individual patient.
Corresponding risk calculators have been traditionally generated relying on traditional statistics. Examples of these include FINRISKI and KardioKompassi -calculators. However, if there is enough data, machine learning algorithms could be applied to create even more accurate calculators that would take into account more factors from the individual’s patient history and thus would create more accurate predictions at the patient level.
Conclusions
Supervised and unsupervised machine learning has lots of material and many stories to be told, so we’ll return to them in a later world of methodologies posts. We might later go through other method families in the field of supervised machine learning, special use cases of classifiers, and general differences between supervised and unsupervised machine learning approaches.
I’d love to hear your thoughts on what you would like to read considering health data, machine learning, and statistical methods. Please write your comments in the comment section of the LinkedIn post related to this blogging.
